Interface graphique de traitement de données RDF, avec une application
géographique
Rapport de stage
Cédric Kiss,
Ingénieur IMAC, promotion ING2003,
Université de Marne-la-Vallée.
Projet SWAD-Europe, IST
The World Wide Web Consortium,
mai à octobre 2003.

Version 2.0 – septembre
2003
Tuteurs de stage
 Charles McCathieNevile, World
Wide Web Consortium (W3C).
Charles McCathieNevile, World
Wide Web Consortium (W3C).
 Didier
Arquès, Université de Marne-la-Vallée (UMLV).
Didier
Arquès, Université de Marne-la-Vallée (UMLV).
Ce stage est effectué dans le cadre de la dernière année d'études à
l'école d'ingénieur IMAC.
Table des matières
- Remerciements
- Présentation de l'environnement de travail
- Présentation du W3C
- L'historique et l'implantation
- La mission du W3C
- Le fonctionnement du Consortium
- Le projet SWAD-Europe
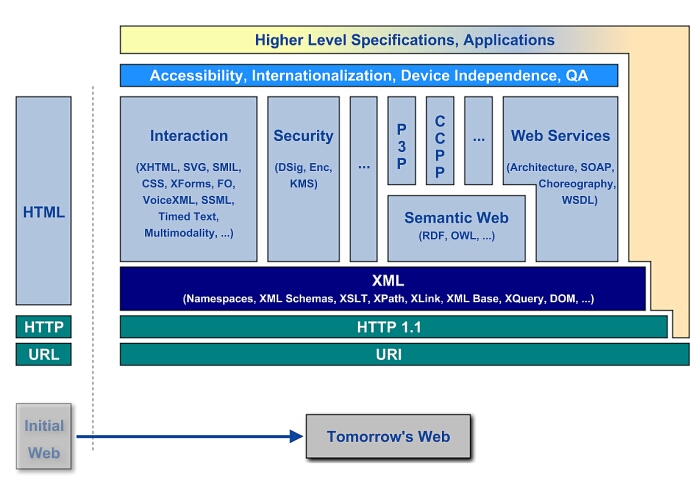
- Présentation des technologies utilisées
- RDF et le Web Sémantique
- Concept du Web Sémantique
- Qu'est-ce que les métadonnées ?
- Écrire du RDF
- Les graphiques avec SVG
- À quoi sert SVG ?
- Syntaxe de SVG
- Promesses et avenir
- Présentation du projet
- Scénario
- À quelle demande répond ce projet ?
- Pourquoi faire un affichage RDF des résultats ?
- Justification des technologies utilisées
- Pourquoi choisir un graphique SVG ?
- Pourquoi choisir un script "côté client" ?
- Pourquoi utiliser le langage ECMAScript objet ?
- Les élements de l'interface
- Les boutons
- Le copier/coller
- Comment se servir du script
- L'existant : le projet FOAF
- L'idée à la base de FOAF
- Format de FOAF
- Implémentations existantes
- Création et évolution de mon fichier FOAF
- Comment je suis arrivé à mon but
- Structure du SVG
- Titres et descriptions des zones
- Zones représentées sans identifiant : porte ouverte à
l'automatisation
- La gestion des sous-zones
- L'élément aéroport et ses coordonnées
- L'élément acteur et ses coordonnées
- L'élément coordonnée
- La liste des aéroports
- Le scutter
- Complications et solutions
- "Violation de sécurité" avec la fonction getURL()
- Un point est-il à l'intérieur ou à l'extérieur d'un polygone
?
- Trouver les données de contours des pays
- Un point peut être dans plusieurs zones
- Trouver le titre d'un élément parmi les noeuds
descendants
- Problème à cause de commentaires dans certains fichiers
RDF
- La lenteur d'exécution
- La gestion des fichiers avec ECMAScript
- La taille des gros fichiers RDF
- Problème d'échelle des éléments graphiques lorsqu'on
zoome
- ECMAScript et l'orientation objet
- Conclusion sur la fin du projet
- Qu'est-ce qui fonctionne ?
- Comment modifier le script pour soi
- Définir des conditions sur les personnes
- Choisir un scutter
- Suivre les pointeurs externes
- Comment améliorer le script
- Utiliser un véritable parser
- Utiliser des ontologies
- Le développement des services de proximité sur le
Web
- Bilan personnel de ce stage
- Mon intégration dans l'entreprise
- Véritable équipe internationale
- Appréciation globale du travail du W3C
- Ma participation dans l'équipe
- Le contrôle de mon projet
- Le codage : une épreuve chronométrée
- Maîtrise de nouveaux outils
- Une vision exhaustive du projet
- Les risques liés à la privacité
- Petit lexique des abréviations
- Bibliographie
- À propos de ce fichier XHTML
- Qu'est-ce que XHTML ?
- Bénéfices de XHTML
- Applications de XHTML
Remerciements
Ce stage, dans une entreprise que je respecte profondément, m'a apporté
beaucoup et s'est déroulé admirablement, notamment grâce à ces personnes que
je souhaite remercier :
- Charles McCathieNevile, W3C Semantic Web Person, pour
son aide précieuse et sa bienveillance spontanée.
- Jérémie Aboiron, professeur de e-Commerce à
l'Université de Marne-la-Vallée, pour son soutien au cours des démarches
et ses contacts au W3C.
Merci sincèrement.
Présentation de l'environnement de travail
Ces paragraphes vont présenter l'entreprise, son
histoire, son but, et le projet dans le cadre duquel se situe le stage,
SWAD-Europe.
Présentation du W3C
L'historique et l'implantation
Le W3C a été fondé en 1994 au Massachusetts Institute of Technology,
Laboratory for Computer Science (MIT/LCS) par Tim Berners-Lee. Il s'est
ensuite implanté en Europe à l'INRIA (en 1995), puis en Asie à l'Université
de Keio, campus Shonan Fujisawa au Japon (1996).
La plupart des 70 chercheurs et ingénieurs qui composent l'équipe du W3C
sont aujourd'hui installés dans ces trois sites principaux, auxquels il faut
ajouter plusieurs bureaux dans de nombreux pays.

Le bâtiment du W3C à l'INRIA Sophia Antipolis.
Il peut mettre à profit cette disposition internationale pour créer des
standards adaptés à tous, en termes de culture, écriture, et besoins.
La mission du W3C
Le W3C poursuit des buts à long terme qu'il identifie ainsi :
- accès universel : rendre le Web accessible à tous en
proposant des technologies qui prennent en compte les vastes différences
de culture, langage, éducation, capacités, ressources matérielles,
appareil d'accès, et limitations physiques des utilisateurs sur tous les
continents. Les activités de ce domaine sont : Web Accessibility
Initiative (WAI), Device Independance, Voice Browser,
Internationalization.
- Web sémantique : développer un environnement logiciel
qui permette à chaque utilisateur de faire la meilleure utilisation des
ressources disponibles sur le Web ; un environnement où les ordinateurs
peuvent interpréter et échanger les données ;
- Web de confiance : guider le développement du Web en
considérant attentivement les problèmes légaux, commerciaux et sociaux
que cette technologie soulève. Ici s'inscrivent les problèmes liés aux
signatures, aux annotations, aux versions... ;
- interopérabilité : les données peuvent être rendues
lisibles à l'aide de n'importe quel logiciel approprié (le format est
issu d'un consensus industriel), langages et protocoles ouverts ;
- évolutivité : s'assurer que le web évoluera facilement
en quelque chose de mieux (les principes de simplicité, modularité,
compatibilité et extensibilité doivent en guider la conception) ;
- décentralisation : une architecture répartie permet
d'éviter les étranglements quand le trafic augmente ; les systèmes
distribués sont également plus flexibles et optimaux pour le trafic web
;
- et du multimédia en ligne plus divertissant : faire un
web plus riche et plus interactif.
"Leading the web to its full potential" : le projet du W3C pour développer le
Web.
Le Web est encore jeune et il y a beaucoup de travail à y effectuer.
L'équipe doit l'accompagner tout au long de son développement, pour s'assurer
que tous les objectifs sont respectés.
Le fonctionnement du Consortium
Le W3C est composé de personnel (architectes, développeurs, consultants),
et de membres (des entreprises de pointe ayant un intérêt dans le
développement des standards). Assemblés en "forum neutre", ils cherchent des
compromis et des solutions nouvelles aux challenges d'aujourd'hui et de
demain.
Ils s'emploient à rendre le Web plus attrayant, plus capable, plus
robuste, et à n'en exclure personne. Le W3C émet ainsi régulièrement des
recommandations pour annoncer les nouveaux langages, formats ou protocoles
(HTML, XML, MathML...). Ces standards peuvent ensuite être implémentés par
n'importe qui, sur n'importe quelle plateforme, librement de droits.
Les activités du W3C sont regroupées en pôles qui peuvent changer en
fonction de la direction que prend le Consortium. Ceux qui sont ouverts en ce
moment sont : Architecture, Interaction, Technology & Society, WAI, et
Quality Assurance.
Le projet SWAD-Europe
La Commission Européenne a investi plus de 3,6 milliards d'euros dans des
activités de recherche en rapport à Information Society Technologies (IST)
— ce qui représente des milliers de projets internationaux dans le
secteur public ou privé. Ceci permet de soutenir le développement européen
sur la scène internationale, et de promouvoir l'adoption par les pays membres
de technologies avancées.
SWAD-Europe est l'un de ces projets. Développé par le W3C dans la branche
T&S, son but est de donner des exemples pratiques où une réelle
plus-value peut être ajoutée au Web au travers du Semantic Web. L'existence
du projet repose sur les points suivants :
- Démontrer la faisabilité et l'utilité des concepts liés au Web
Sémantique ;
- Développer des composants qui puissent former la base pour une
infrastructure de Web Sémantique à grande échelle ;
- Explorer les problèmes de recherche de pointe nécéssaires pour le Web
Sémantique mais pas encore prêts pour la standardisation.
Dans cet esprit, SWAD-Europe couvre une large gamme d'applications où le
Semantic Web simplifie les tâches humaines. De grandes universités et
entreprises privées y participent ; on y retrouve plusieurs chercheurs déjà
connus notamment pour leur travail sur les métadonnées.
Présentation des technologies utilisées
Beaucoup de nouvelles technologies sont utilisées pour
ce projet ; en voici une brève présentation, pour pouvoir mieux appréhender
son fonctionnement.
RDF et le Web Sémantique
Concept du Web Sémantique
L'activité Web Sémantique du W3C tend à étendre l'architecture existante
du Web en ajoutant de l'information communicable à propos de ressources qui
peuvent ensuite être analysées par des agents automatisés. C'est un médium
universel, décentralisé et intelligent, pour échanger des informations sur le
Web.
Le RDF (Resource Description Framework) est le langage qui véhicule ces
informations. Comme son nom l'indique, c'est un langage de description. Son
avantage est une très grande flexibilité, qui lui permet de pouvoir s'adapter
à toutes sortes d'applications.
Qu'est-ce que les métadonnées ?
"Méta" est utilisé pour tout ce qui est à propos de soi-même — ainsi un
métalivre serait un livre à propos des livres, et une métadonnée est une
donnée à propos de données. Sur le Web, ceci désigne toute sorte
d'informations à propos d'informations : son propriétaire, auteur, ses droits
de reproduction, sa politique de privacité, etc. Ces besoins nous poussent à
créer des façons de stocker de l'information sur le web, conçue pour que les
ordinateurs soient capables de la comprendre.
Les pages Web d'aujourd'hui, en HTML, sont écrites pour être lues par des
humains. Dans le futur, certaines pages Web seront en RDF. Elles seront lues
par des programmes informatiques qui nous aideront à nous organiser, ainsi
que nos données, et que tout ce que nous pourrions éventuellement faire.
Écrire du RDF
RDF n'est pas un format, c'est un langage. À ce titre,
il est supposé être indépendant du format (qui n'est pas imposé). On peut
l'écrire en n-triples, un format assez facile à appréhender pour un
humain.
Exemple : représentation de l'assertion "La ressource
http://www.example.org/index.html a une date de création dont la valeur est
le 16 août 1999".
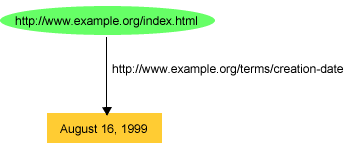
Représentation graphique de l'assertion.
En n-triples, ceci donnerait :
ex:index.html exterms:creation-date "August 16, 1999" .
Une autre façon simple d'écrire le RDF est d'utiliser le XML (format
RDF/XML), un standard créé par le W3C. Les machines peuvent le traiter
facilement (car c'est un standard répandu), et on bénéficie de tous les
avantages de XML (contrôle par DOM, transformations XSLT, lisibilité...).
L'assertion ci-dessus, dans une syntaxe RDF complète, donne :
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.org/index.html">
<exterms:creation-date>August 16, 1999</exterms:creation-date>
</rdf:Description>
</rdf:RDF>
Les graphiques avec SVG
À quoi sert SVG ?
SVG (Scalable Vector Graphics) est un langage récent et prometteur, qui
permet de créer des graphiques 2D vectoriels facilement accessibles via le
Web. De nombreuses primitives existent déjà dans le langage (courbes de
Bézier, dégradés, texte) qu'il est possible d'utiliser avec un minimum de
peine. Interfacé avec SMIL il permet de faire des animations. Il est, de
plus, dynamique et interactif grâce à son support DOM, et supporte
l'exécution de scripts.
Il est actuellement possible de lire des SVG avec des logiciels gratuits
ou open-source. On citera par exemple le plus déployé, Adobe SVG Viewer, et
un second développé en Java, Batik.
Syntaxe de SVG
Le SVG s'écrit en XML (son type de contenu est alors image/svg+xml). Voici
un exemple de création d'un graphique simple (composé d'un texte, d'un
rectangle et d'un cercle) :
<svg>
<title>Un test</title>
<text x="5" y="120">Voici un graphique simple</text>
<rect x="10" y="50" height="50" width="90" fill="blue"/>
<circle cx="80" cy="45" r="40" opacity="0.6" fill="yellow" stroke="black"/>
</svg>
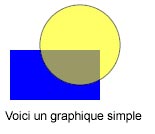
Un graphique simple SVG composé d'un rectangle, d'un cercle et d'un texte.
Comme d'autres langages en XML, la maintenance est particulièrement
facilitée par une structure claire, des noms d'éléments explicites, et une
taille de fichier raisonnable.
Promesses et avenir
SVG convoie de nombreuses promesses car c'est un langage très puissant,
facile à générer (par un humain, par XSLT, ou par n'importe quel script d'une
machine), libre de droits, et interopérable (compatible, capable de tourner
sur différents ordinateurs à travers différentes applications).
C'est déjà le format préféré des professionnels de la cartographie (le
lobby GIS), et de nombreux chercheurs et scientifiques. De par sa nature
"ouverte", il pourrait supplanter, voire remplacer Macromedia Flash (dont
l'utilité est légèrement similaire, mais le format complètement propriétaire
et écrit en binaire).
Toujours en développement, une version 1.2 est actuellement à l'étude.
Parallèlement à l'évolution du format HTML (la modularisation permettra
d'intégrer de nouvelles fonctionnalités), on pourra bientôt en dessiner
directement dans les pages Web (sans besoin d'une application externe
supplémentaire).
Présentation du projet
Scénario
À quelle demande répond ce projet ?
Mon tuteur souhaitait disposer d'un script qui puisse l'aider à localiser
des gens (développeurs sur le Semantic Web) dès sa sortie de l'aéroport. D'un
point de vue scénaristique, le développement des bornes internet sans fil
dans les lieux publics rend cette histoire plausible.
C'est un cas pratique intéressant, puisque cela suggère un format adapté
et une interface d'une grande clarté, pour pouvoir être efficace rapidement
dans un environnement "agité".
Pourquoi faire un affichage RDF des résultats ?
Il y a deux façons de lire les résultats du script : un affichage
ordinaire à l'écran, et une sortie en format RDF. L'affichage à l'écran est
évidemment très utile pour un humain, et est nécéssaire car il permet :
- de connaître les réponses !
- de pouvoir se rendre compte si le script s'est trompé.
Mais une machine est incapable de traiter la sortie d'un résultat adapté à
un être humain, car un tel résultat n'est pas assez structuré. Une sortie RDF
sur ce même écran permet alors d'exporter le code et de le faire traiter par
une autre application.
Justification des technologies utilisées
Pourquoi choisir un graphique SVG ?
De par sa nature fondamentalement vectorielle, SVG est tout à fait
recommandé pour les applications cartographiques. Dans ce script on va se
servir non seulement des vecteurs (contours des pays, emplacement des
aéroports), mais aussi des rasters (image de la Terre représentant les
couleurs de la mer, des déserts et des forêts), et également de contrôler des
animations sur n'importe quel objet graphique (création d'éléments, zooms,
rotations, etc.). On a notamment la possibilité d'utiliser les fonction de
zoom avant et arrière, afin de préciser davantage le champ de notre
recherche.
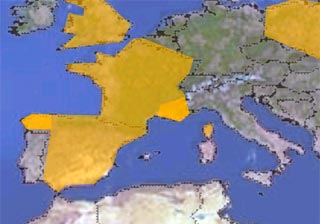
Quelques contours de zones sont ici représentés (en basse résolution) à
l'aide de polygones oranges, au-dessus d'une photo de la Terre.
D'autre part, c'est un langage particulièrement léger. SVG, comme toutes
les recommandations du Consortium, est conçu pour être utilisé sur le Web :
le transfert des informations, la taille des fichiers, le chargement des
informations externes y sont optimisés.
De plus, comme toute recommandation W3C digne de ce nom, SVG profite des
possibilités offertes par XML (comme la lisibilité et l'internationalisation)
et y ajoute ses propres extensions de fonctionnalités (accessibilité,
compatibilité avec des machines inférieures...). Sa nature ouverte, proche de
la communauté de la recherche, le rend de plus en plus "inévitable".
Côté script : nous allons devoir modifier le graphe à la volée, au fur et
à mesure qu'on obtient ces fameuses données issues du Web Sémantique. Pour
cela nous allons utiliser la technologie la plus largement implémentée et la
plus facile à mettre en oeuvre : la dynamisation par le DOM. Ainsi nous
pourrons créer des éléments graphiques SVG interactifs autant que nous en
aurons besoin.
De plus, comme on utilise deux formats basés sur une syntaxe XML, on peut
espérer obtenir une certaine uniformité dans le fonctionnement de
l'application et l'intégration des informations. Ce n'est pas une condition
nécéssaire (heureusement) mais cela permet de n'utiliser qu'un nombre réduit
d'interfaces.
Pourquoi choisir un script "côté client" ?
Nous avons d'abord considéré les différentes possibilités offertes par les
deux options, côté client (le script est exécuté par le client) ou côté
serveur (le script est envoyé "tout fait" au client).
Arguments en faveur de l'exécution côté serveur :
- Connexion en général plus rapide ;
- les résultats du script ne sont pas affectés par les capacités du
client (par exemple, si on a besoin de faire des opérations complexes
mais d'afficher les résultats sur un appareil mobile, tel un téléphone
portable).
Arguments en faveur de l'exécution côté client :
- Le fichier à transmettre est beaucoup plus petit ;
- le serveur gère beaucoup plus de charge de calcul ;
- on a accès au code source. Ceci peut être un défaut pour des
applications spécifiquement commerciales (recopie de code plus facile,
etc.).
Pourquoi utiliser le langage ECMAScript objet ?
ECMAScript (JavaScript) est le langage de script attitré des graphiques
SVG. Il permet de dynamiser et de modifier l'affichage.
L'idée, pour que ce projet ne dépérisse pas à la fin du stage, est d'en
faire le code le plus lisible possible. L'approche objet du codage est
particulièrement bien adaptée dans un environnement où plusieurs personnes en
assureront la programmation : extensibilité, facilité de relecture, clarté
sont autant de qualités qui font espérer une plus grande pérennité au
travail. De plus, on se rapproche ainsi de la structure des fonctions
utilisant le DOM, ce qui permet de comprendre plus instinctivement
l'utilisation de ces fonctions et méthodes.
// Création d'un acteur
var monNom="Cédric";
var cedCodeAirport="NCE";
var cedPhoto="http://ckiss.net/cedric/photo.jpg";
var cedFoafFile="http://ckiss.net/cedric/foaf.rdf";
var cedEmail="mailto:cedric2003@ckiss.net";
var Ced=new Actor(monNom,cedCodeAirport,cedPhoto,cedFoafFile,cedEmail,Coords(47,2));
Par exemple, les fonctions getElementsByTagName() et
getImmediateChildrenByTagName() (qui retourne la liste des
éléments d'un certain nom) ont une certaine uniformité de syntaxe ; il est
aisé de passer d'une fonction à l'autre. De même, la méthode
draw() a un nom parlant et univoque, et est déclinée pour tous les
objets du script.
Les élements de l'interface
Les boutons
Dans le souci d'avoir une interface claire et répondant aux critères
d'ergonomie, le but est de mettre le moins de boutons possible, et de ne
garder que les plus utiles ! Au cours du développement il y en a eu beaucoup,
mais en essayant d'automatiser un maximum de tâches, on peut se permettre de
ne laisser uniquement que ce qui concerne :
Pour afficher les résultats de la recherche d'aéroports, de chargement de
fichiers, d'affichage de pays. Ceci permet de savoir si le script fonctionne
correctement, si les résultats sont justes.
- Les informations et résultats
Un seul bouton affiche les résultats dans le format humain et dans le
format RDF.

Les quatre commandes du script.
Le copier/coller
Le copier/coller (déplacement de texte entre différentes applications) est
une fonctionnalité qu'on rencontre avec SVG, mais pas en Flash par exemple,
ni dans la plupart des applications Java. Ceci nous fournit un moyen pratique
de transférer le code généré par notre script vers une autre application.
Sinon, on aurait pu créer un fichier externe comportant le code RDF, mais
ce n'est pas pour le moment possible avec seulement un navigateur SVG.
Comment se servir du script
Voici, de façon chronologique, comment on peut se servir du script :
- Codage de la condition sur les personnes, si nécéssaire ;
- Chargement de tous les contours des pays ;
- Dessin des contours des pays sur la carte ;
- Chargement de tous les aéroports ;
- Dessin des aéroports ;
- Chargement du "scutter" ;
- Chargement des fichiers FOAF indiqués par le scutter ;
- Recherche sur le Web des aéroports manquants dans notre fichier
airports.rdf ;
- Localisation des acteurs trouvés dans les fichiers FOAF ;
- Dessin des acteurs sur la carte ;
- Se promener, zoomer sur la carte pour trouver la position qu'on cherche
;
- Cliquer sur la carte pour communiquer pour quelle position on veut des
informations ;
- Demander les résultats au script.
L'existant : le projet FOAF
FOAF est un projet important pour le Web Sémantique,
car il a plusieurs applications pratiques et regroupe de nombreuses
données.
L'idée à la base de FOAF
FOAF (Fiend-of-a-Friend, l'ami d'un ami) est un projet et un vocabulaire
expérimental pour le Web Sémantique. C'est une initiative pour créer une
société de personnes, définies par leurs informations. Il permet de relier
des personnes à d'autres (d'où le titre du projet) et d'avoir accès à des
données personnelles telles que leurs occupations, leur adresse, et tout ce
qu'on désire. Il est basé sur l'idée d'une version lisible par les machines
du World Word Web actuel, avec des pages d'accueil, des listes de diffusion,
des itinéraires de voyage, calendriers, carnet d'adresses, etc. Évidemment,
comme n'importe quel vocabulaire RDF, il est facile de l'augmenter comme on
le souhaite (en incluant les langues parlées, les positions
géographiques...). Il sera une base du travail de ce projet, car on pourra
alors réutiliser les données de FOAF pour nourrir notre script.
Format de FOAF
En pratique, la communauté FOAF est "matérialisée" par une foule de petits
fichiers RDF/XML où des personnes laissent des informations les concernant :
nom, adresse mail, intérêts... et évidemment, on ajoutera les personnes qu'on
connaît (son entourage).
Petite spécificité : on considère qu'une personne est identifiée de
manière unique en fonction de son adresse mail.
<foaf:Person>
<foaf:mbox>cedric2003@ckiss.net</foaf:mbox>
</foaf:Person>
Implémentations existantes
Sur la base de FOAF, de nombreuses applications sur de nombreuses
plateformes peuvent éclore. Plusieurs implémentations à succès commencent à
démontrer la puissance du Web Sémantique, dont le Foafnaut (un navigateur qui
trace les relations entre les personnes) ; le FOAF People Map (qui place ces
personnes sur une carte) ; le FOAF Web View (qui crée des pages web contenant
le résultat des informations RDF) ; etc.
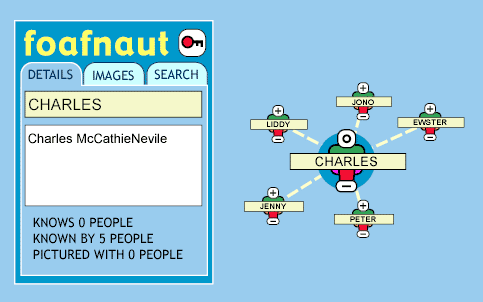
Une capture d'écran de Foafnaut.
La flexibilité du format permet d'avoir des applications différentes avec
pourtant un fichier unique de données par personne.
Création et évolution de mon fichier FOAF
Afin de participer à l'aventure, de me familiariser avec le langage RDF,
et de tester mon script "sur moi-même", j'ai fait un fichier FOAF me
décrivant. En voici les étapes :
- Nom : il existe plusieurs façons de décrire son nom (est-ce mon surnom
? est-ce le nom qu'on me donne ?) ;
- Adresse : il est possible, dans le vocabulaire, de chiffrer mon adresse
e-mail (ce qui la protège des mailings non sollicités) ;
- Personnes connues : on peut ajouter toutes sortes d'informations (ou
aucune !) sur les personnes qu'on prétend connaître ;
- Localisation : de nombreuses personnes donnent des informations
supplémentaires révélant leur position, soit sous forme de coordonnées
(latitude/longitude/altitude), soit en révélant quel aéroport est le plus
proche.
Comment je suis arrivé à mon but
Description et justification des choix techniques à
l'occasion du développement de ce projet.
Structure du SVG
Titres et descriptions des zones
Avoir une structure claire permet une relecture et une évolutivité aisées.
C'est également un critère d'efficacité et on doit prendre en compte que la
création des structures sera automatisée, puis relue par le script au cours
de l'exécution. C'est pourquoi elle a bénéficié d'une grande attention au
cours de ce projet.
En plus des éléments géométriques, on a utilisé l'élément title spécifié
dans SVG pour décrire rapidement les différentes régions. On pourrait
évidemment "modulariser" le doctype (la définition des éléments qui
composent un document) SVG en y ajoutant des noms d'éléments, pour y inclure
des fonctionnalités de description plus avancées.
Zones représentées sans identifiant : porte ouverte à
l'automatisation
Pendant les tests, les zones possédaient un identifiant unique
"id", fonctionnalité du DOM XML. Ceci permettait de tester les
zones identifiées. Par "tester" je veux dire par exemple, déterminer si un
point SVG (530,120) est à l'intérieur d'un polygone fermé de points
(500,100)(550,100)(500,200). Si le point sélectionné est à l'intérieur du
polygone, l'analogie est la suivante : on est à l'intérieur de cette région
d'identifiant id="un_identifiant".
Par la suite, la meilleure façon de faire a été de ne pas mettre
d'identifiant aux zones, et de se servir seulement du "handle" qu'on récupère
en accédant à la liste des sous-éléments XML. Sans identifiant unique, un
nombre infini de zones peuvent être générées automatiquement lors du
chargement des fichiers externes — et c'est ce que nous voulons.
<g id="turquie">
<title xml:lang="fr">Turquie</title>
<zoneType xml:lang="fr">Pays</zoneType>
<path id="turquieEurope" d="..."/>
<path id="turquieAnatolie" d="... ... ..."/>
</g>
La gestion des sous-zones
On écrira en SVG une zone comme étant un élément "g" (ce qui correspond à
un groupement de n'importe quels éléments SVG). Ainsi on pourra inclure dans
la même zone (Turquie) plusieurs polygones (Anatolie, Europe) se référant à
un même titre et une même description.
Les zones peuvent également contenir d'autres sous-zones de même type (de
même structure). Ceci permet d'obtenir autant de niveaux de précision que
désiré. J'y ai mis les informations suivantes :
Une zone (dans un élément "g") contient :
- <title> (le titre de la zone, par exemple,
"France")
- <zoneType> (le type de zone : continent, ville... Ceci
pour dire "vous êtes dans le même continent...", et introduire
un niveau de précision. On pourra émettre l'hypothèse que "continent >
pays > région", et ensuite, pourquoi pas, demander "restreindre la
recherche à la même ville, au même pays, etc. que moi".
- la forme : ce qui décrit la forme d'une zone est une primitive de SVG
appelée "path". C'est un polygone représentant la forme de la zone sur la
carte SVG.
L'élément aéroport et ses coordonnées
D'autres éléments que les pays devront se rajouter à la carte pour pouvoir
l'utiliser. On a dit qu'on se servirait des positions des aéroports, qui
certes sont d'un niveau de précision assez bas (le code "CDG", correpondant à
l'aéroport Charles-de-Gaulle, siginfie-t-il Marne-la-Vallée ? Cergy-Pontoise
?) mais c'est un système :
- qui est facile à mettre en oeuvre (beaucoup de gens connaissent le nom
de l'aéroport le plus proche, ou peuvent le localiser sur une carte du
moins, parmi d'autres aéroports)
- qui respecte tout de même la privacité des individus, car assez
vague.
Pour traîter efficacement les aéroports du monde, on a créé un objet
Airport qu'on stocke dans un tableau (nommé Array en EMAScript).
Voici la structure de Airport :
- name (le nom usuel de l'aéroport, par exemple : "Nice Côte
d'Azur")
- iata (le code IATA à 3 lettres de l'aéroport : "NCE")
- icao (le code ICAO à 4 lettres de l'aéroport : "LFMN")
- coords (les coordonnées : Array(41N,6E))
On a tout ce qu'on souhaite pour :
- l'afficher à l'écran (on utilise les coordonnées et le titre) ;
- retrouver l'aéroport (dans le vocabulaire RDF
contact:nearestAirport, on peut l'identifier par le code IATA
et/ou le code ICAO).
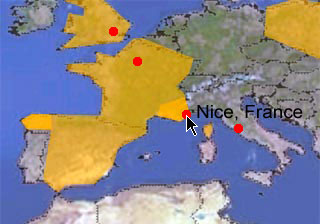
Quelques aéroports placés sur la carte, représentés par des points rouges.
L'élément acteur et ses coordonnées
Pour localiser les participants au graphe (humains par exemple), on a
besoin d'extraire des informations. L'ordinateur a une mémoire finie, le
nombre d'utilisateurs de FOAF est très grand, et chaque fichier FOAF peut
contenir beaucoup d'informations hétéroclites et/ou "déjà vues"... on devra
donc ne pas noter toutes les informations ; on devra ne garder que les
informations qui nous intéressent spécifiquement pour notre projet.
On évincera à la volée, les participants qui n'auront pas les centres
d'intérêt qu'on voudra sélectionner. Par exemple, pour organiser un meeting
sur le Web Accessibility Initiative, on regardera seulement où se trouvent
les personnes impliquées dans le projet WAI. Ceci peut se décrire en RDF par
:
<foaf:interest>
<rdf:Description>
<dc:title>WAI (Web Accessibility Initiative)</dc:title>
</rdf:Description>
</foaf:interest>
<!-- ou encore -->
<foaf:interest>
<foaf:Organization>
<foaf:homepage rdf:resource="http://www.w3.org/WAI"/>
</foaf:Organization>
</foaf:interest>
Ce qui veut dire : "j'ai un centre d'intérêt qui est le projet WAI", ou
"j'ai un centre d'intérêt qui a une page web dont l'URL contient WAI" (ce qui
revient au même).
On regardera donc dans tout le noeud <foaf:interest> pour
y trouver des renseignements dans les valeurs des éléments descendants
(childNodes.firstValues avec DOM) et dans les valeurs des
attributs des éléments (dans les rdf:about par exemple), au cas où
seul 1 des deux serait rempli. Il est pour l'instant difficile de traîter
mieux ce problème seulement avec ECMAScript ; au moins, on récupère
effectivement tous les participants qui ont entré SWAD dans leurs
intérêts.
Les objets Actor, regroupés en tableau, contiendront les
informations suivantes qu'on aura pu récolter de notre moisson :
- name (le nom utilisé par la personne, par exemple : "Cédric
Kiss")
- aptCode (le code de l'aéroport, s'il est indiqué :
"NCE")
- photoUri (l'adresse distante d'une photo de la personne, si
applicable)
- foafUri (l'adresse distante du fichier FOAF de la personne,
si applicable)
- mailbox (l'adresse e-mail :
"mailto:cedric2003@ckiss.net")
- coords (les coordonnées géographiques de la personne)
L'élément coordonnée
On utilisera l'objet Coords. Il peut ou non prendre en compte l'altitude
(même si le script ne s'en sert pas).
Coords :
- latitude ;
- longitude ;
- altitude.
Une fonction était nécéssaire pour retrouver directement les coordonnées
géographiques correspondant à un code d'aéroport donné. Voici comment se
servir de getAirportCoords() :
// Cédric est à l'aéroport CDG
coordsCedric=getAirportCoords('CDG');
window.alert(coordsCedric);
// Affiche : Coordonnées : lon=47N ; lat=2E ; alt=undefined
La liste des aéroports
Pour afficher tous les aéroports sur la carte, ce qui est une donnée sans
grand dynamisme (ne change pas ou peu au cours des années), on utilise un
fichier "tout fait" où plusieurs centaines d'aéroports sont décrits en RDF.
On accède au fichier (compressé) et au cours du décodage, on stocke les
aéroports dans le tableau. À la fin de cet exercice, tous les aéroports
connus par ce fichier sont dessinés sur la carte en fonction de leurs
coordonnées (latidute/longitude) et de leur taille (on donne arbitrairement
rouge pour les petits et jaune pour les grands, pour pouvoir se repérer plus
facilement).
<!-- Exemple de description d'un aéroport dans le fichier RDF-->
<apt:Airport rdf:about="http://www.megginson.com/exp/id/airports/BIKF">
<apt:icao>BIKF</apt:icao>
<apt:name>Keflavikurflugvollur, Iceland </apt:name>
<apt:iata>KEF</apt:iata>
<apt:latitude>63-58N</apt:latitude>
<apt:longitude>022-36W</apt:longitude>
<apt:elevation>54M</apt:elevation>
</apt:Airport>
Lorsqu'on cherche l'aéroport qu'une personne donne comme le plus proche
d'elle (contact:nearestAirport), et que celui-ci n'existe pas dans
le fichier, on utilise une méthode alternative pour en retrouver le nom et
les coordonnées. On envoie une requête sur le Web avec le code d'aéroport en
paramètre. On récupère ensuite le flux de données RDF qui nous est renvoyé,
on l'interprète, et on ajoute ce résultat au tableau d'aéroports.
Le scutter
Il est plus compliqué de parcourir tous les fichiers décrivant des gens
sur le Web. Daniel Brickley et Jim Ley par exemple ont créé des fichiers qui
regroupent les adresses des fichiers FOAF connus (ce qu'ils appellent un
scutter). Il est ainsi possible de récupérer le fichier de ce
scutter (un fichier RDF de 300 Ko, regroupant les adresses de plus de 3000
fichiers de personnes). En analysant ce scutter, on peut envoyer des requêtes
aux adresses indiquées, puis les récupérer.
loadScutter(scutter.xml);
fonction loadScutter(){
tantque(lecture du fichier){
// Cherche les informations sur cette personne
getAirportFromFoafFile();
}
}
fonction getAirportFromFoafFile(){
// ajoute l'acteur au tableau d'acteurs
}
Complications et solutions
Voici quelques problèmes que j'ai rencontrés au cours
de ce projet, et quelques solutions qui ont été préconisées.
"Violation de sécurité" avec la fonction getURL()
La visionneuse de SVG la plus évoluée, qui est utilisée pour faire tourner
ce script, permet aussi des fonctions de chargement de fichier.
Malheureusement, pour des raisons de sécurité, seuls les fichiers présents
sur le même serveur ont le droit d'être accédés. Exemple : si je lance le
script sur le serveur www.w3.org, je ne pourrai pas récupérer un fichier
stocké sur le serveur jibbering.com.
Pour contourner ce problème, nous avons mis sur place un petit "proxy" en
PHP, qui est un petit script (placé sur le serveur de notre projet) qui
accède des pages distantes et les renvoie à la machine qui a appelé.
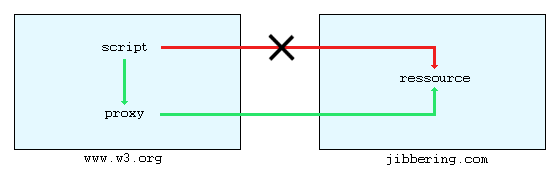
Utilité du proxy
Un point est-il à l'intérieur ou à l'extérieur d'un polygone ?
SVG dispose d'une méthode native permettant de se déclencher dès qu'un
utilisateur clique sur un élément graphique.
<svg>
<!-- Affiche "Vous avez cliqué" lorsqu'on clique sur le rectangle -->
<rect x="10" y="50" height="50" width="90"
onclick="window.alert('Vous avez cliqué')"/>
</svg>
En revanche, il n'existe pas de fonction permettant de révéler si un point
du graphe est contenu dans un polygone. Il a donc fallu créer cette fonction,
qui fait appel aux mathématiques.
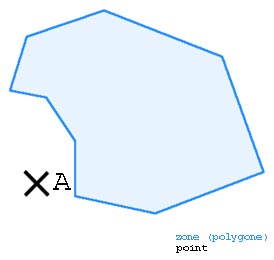
Le point est-il contenu dans le polygone ?
Trouver les données de contours des pays
De nombreuses données géographiques sont disponibles sur le Web, mais sont
malheureusement souvent dans un format binaire propriétaire, ou payantes.
Nous avons trouvé un site mettant à disposition gracieusement la liste des
points formant les contours des pays du monde, sous format texte. Une
conversion à la main est nécéssaire pour en sortir un fichier RDF exploitable
:
<!-- Exemple de fichier RDF pour la zone : Arizona -->
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:area="http://ckiss.net/machin/area-ns#">
<area:Area>
<area:name>Arizona</area:name>
<area:polygons>
<area:Polygon>
<area:center>
-112.353981 33.391022
</area:center>
<area:points>
-109.046196 31.331800
-109.300354 31.334017
-109.789291 31.332031
<!-- (Ici devrait avoir lieu l'énumération de chaque point) -->
-109.048943 31.806059
-109.045547 31.508570
-109.046196 31.331800
</area:points>
</area:Polygon>
</area:polygons>
</area:Area>
</rdf:RDF>
Un point peut être dans plusieurs zones
Lorsqu'on a défini des zones précises (comme une ville) et des zones moins
précises (comme un pays), on doit pouvoir comprendre qu'un point est dans une
ville qui elle-même est contenue dans un pays. Le résultat d'une telle
recherche n'est donc pas une seule zone : c'est un tableau de zones. Le
script est paramétré pour retrouver toutes les zones dans lesquelles est
contenu ce point, puis ordonner ces zones pour donner un résultat tel que
"Galicie, Espagne, Europe" où Galicie ⊂ Espagne ⊂ Europe.
De plus, on considère que si on clique sur une frontière entre 2 zones
distinctes (par exemple, la frontière franco-espagnole), le script doit
retourner toutes les localisations impliquées (il y aura donc 2 résultats, un
pour "France", et un pour "Espagne"). Le résultat retourné par la fonction
qui récupère le nom des zones qui contiennent un point, est donc un tableau
de tableau de zones.
Trouver le titre d'un élément parmi les noeuds descendants
Un gros problème est survenu lors de deux exercices :
- récupérer le titre d'une zone, sachant qu'il existe
des sous-zones
<!-- Dans ce code, deux "titles" sont descendants du g nommé "spain" -->
<g id="spain">
<zoneType>Pays</zoneType>
<title>Spain</title>
<g>
<path class="countryOutlines" d="M 496.125 134.25 [...] Z"/>
</g>
<g>
<zoneType>Région</zoneType>
<title>Galicia</title>
<path class="countryOutlines" d="M 482.5 129.125 [...] Z" />
</g>
</g>
- récupérer les coordonnées d'une personne, sachant
qu'une personne "contient" les personnes qu'elle connaît.
<!-- Dans ce code, il y a un code d'aéroport qui est descendant de la personne "principale", -->
<!-- mais qui ne décrit pas cette personne "principale" -->
<foaf:Person>
<foaf:name>Cédric Kiss</foaf:name>
<foaf:mbox>mailto:cedric2003@ckiss.net</foaf:mbox>
<foaf:knows>
<foaf:Person>
<foaf:nick>danield</foaf:nick>
<contact:nearestAirport>
<wn:Airport air:iata="NCE"/>
</contact:nearestAirport>
</foaf:Person>
</foaf:knows>
</foaf:Person>
Dans ces deux cas le risque était de récupérer le titre d'une mauvaise
zone, ou les coordonnées d'une autre personne. Le souci provient de la
fonction getElementsByTagName() qui récupère tous les éléments
d'un certain nom, par exemple,
getElementsByTagName('contact:nearestAirport').
Par exemple, les résultats d'une fonction utilisant cette méthode seraient
de dire que la personne "Cédric Kiss" a un aéroport le plus proche identifié
par son code "NCE"...
Pour avoir le bon titre, ou le bon aéroport, on doit récupérer la liste
des descendants, et tester si le noeud parent de l'élément trouvé (un titre
est un élément descendant) est effectivement l'élément testé. C'est le
principe de la fonction getImmediateChildrenByTagName() que nous
avons créée pour pallier à ce problème.

Parmi les wn:Airport descendants de l'élémant racine, certains ne
correspondent pas à ce qu'on cherche.
Problème à cause de commentaires dans certains fichiers RDF
Une difficulté assez étonnante était de trouver le commencement d'une
structure dans un fichier XML. Normativement, tous les éléments d'un document
XML sont regroupés dans un même noeud. Pour analyser un fichier XML, il faut
trouver le noeud racine et étudier ses descendants.
<?xml version="1.0" encoding="utf-8"?>
<!-- Voici une ligne de commentaires. -->
<!-- En voici une autre. -->
<!-- Les commentaires sont fréquemment utilisés -->
<!-- dans les fichiers XML. -->
<rdf:RDF>
<!-- Les informations viennent ici... -->
</rdf:RDF>
Le fonctionnement de ce projet supposait de retrouver une foule de fichier
RDF à travers l'Internet. De par la nature des fichiers RDF, que l'on peut
écrire "à la main" muni d'un simple éditeur de texte, la façon de les écrire
peut changer grandement d'un "auteur" à un autre. Or dans certains cas,
certaines fonctions étaient capables d'analyser certains fichier RDF, mais
pas d'autres. Nous avons compris quelles différences déclenchaient ces
singularités :
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF>
<!-- un contenu -->
</rdf:RDF>
et
<?xml version="1.0" encoding="utf-8"?>
<!-- Fichier créé le 12 août 2003 -->
<!-- (Note : ce fichier ne fonctionnait pas avec notre analyseur) -->
<rdf:RDF>
<!-- un autre contenu -->
</rdf:RDF>
Ces deux codes mis côte-à-côte, la différence saute aux yeux : les
commentaires sont considérés par l'analyseur ECMAScript comme des "noeuds" (à
tort ou à raison ?). Ainsi, lorsqu'on récupère le "handle" du
premier élément, on n'obtient alors pas la racine du document, mais un
commentaire. Pour avoir le vrai élément racine, on va donc tenter de
récupérer "le premier élément" jusqu'à ce qu'il ait des descendants (ce qui
signifierait que c'est le noeud racine qu'on cherchait) :
// On "saute des lignes" (jusqu'à 100) jusqu'à ce qu'on ait trouvé la racine du document XML.
var myAirport=false;
for(var a=0; a<100; a++){
try{
myAirport=externNode.childNodes.item(a).getElementsByTagName('airport:Airport');
}catch(erreur){}
if(myAirport){
window.alert('trouvé après '+a+' lignes de commentaires');
break;
}
}
La lenteur d'exécution
Pour tracer les contours des pays on utilise donc des fichiers en haute
résolution. Ceci signifie que pour savoir si un point est à l'intérieur d'une
zone, on doit le comparer à chaque zone — chacune ayant des milliers
de coordonnées ! Pour résoudre ce problème, on a utilisé les parades
suivantes :
Si au lieu de travailler avec 5000 points, on en utilise 1/10, le calcul
se fait naturellement plus rapidement, mais au détriment de la précision.
Il existe dans SVG un attribut boundingBox, qui donne le
rectangle dans lequel est tracé un polygone ou une forme quelconque.
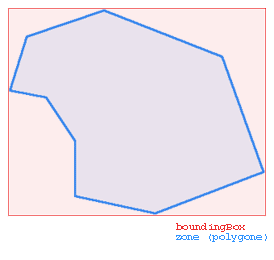
Représentation d'un boundingBox SVG (en
rouge)
Une idée pour accélérer les tests sur chaque zone, est de regarder si un
point est à l'intérieur de ce rectangle. Si oui, on teste "normalement" ; si
non, il n'y a aucune chance pour que le point soit contenu dans le polygone,
et on ne teste pas.
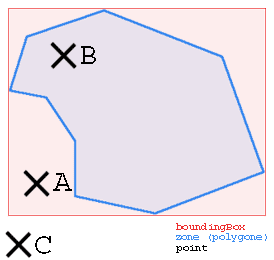
Contrairement aux points A et B, le point C n'a aucune chance d'être contenu
dans le polygone.
Ceci augmente considérablement la vitesse des tests.
- L'analyseur syntaxique ECMAScript
Nous utilisions un analyseur syntaxique RDF "déjà fait" par un autre
membre de la communauté RDF Interest Group, mais ce script n'était
malheureusement plus capable de fonctionner lorsqu'il devait traiter
plusieurs fichiers à la fois (sur des processus différents). C'est pourquoi
nous avons fait nos propres fonctions, moins évoluées, mais plus adaptées à
cet environnement. Une conséquence non escomptée de ce revirement a été de ne
plus être obligés d'utiliser le parser ECMAScript d'Adobe SVG Viewer. En
effet, moyennant quelques reformulations et adaptations, le projet était
capable de tourner également sous le parser ECMAScript du navigateur Web.
Celui-ci, imparfait, mais suffisamment efficace pour le projet, est
heureusement bien plus rapide que le précédent. Ce choix a définitivement
réduit la durée de calcul à quelques secondes.
La gestion des fichiers avec ECMAScript
En se passant d'un identifiant pour chaque élément "g", une façon simple
et parfaitement dans l'esprit de RDF aurait été de prendre le nom du fichier
comme descripteur unique. Malheureusement, la fonction getURL ne permet pas
d'associer en aucune façon le contenu d'un fichier récupéré à son nom du
fichier. En effet, après que la fonction ait été appelée, le script continue
à s'exécuter normalement — et c'est un processus (thread)
séparé qui reçoit le signal comme quoi le fichier externe a été chargé.
La solution adoptée est de rajouter un descripteur unique dans le contenu
du fichier externe RDF. Ceci concorde aussi avec le concept de RDF :
<area:SubArea rdf:about="http://www.az.gov/#">
<area:name>Arizona</area:name>
<rdfs:seeAlso rdf:resource="arizona2pts.rdf"/>
</area:SubArea>
Ainsi on peut espérer avoir un identifiant univoque lorsqu'on parle d'une
zone (par exemple, ne pas confondre la zone Géorgie contenue dans la zone
états-Unis, avec la zone Géorgie au bord de la Mer Noire : ici le titre de la
zone n'est pas un descripteur unique).
La taille des gros fichiers RDF
XML est un format texte (le contraire de binaire), lisible avec
un simple éditeur de texte. Par voie de conséquence, XML et a fortiori RDF
requièrent beaucoup de place pour écrire des données — c'est un des
"coûts" de ce type de format. Fort heureusement, du fait de la répétition des
balises, un codage entropique peut facilement diviser la taille des gros
fichiers XML par un facteur 10.
// Charge et traîte le fichier
getURL('airports.rdf', drawAirportsFromFile);
La visionneuse de SVG que nous utilisons, Adobe SVG Viewer 3, permet de
décoder le format de compression GZIP (LZ) de façon transparente. Ainsi, on
peut compresser un fichier volumineux, tel que celui qui contient tous les
aéroports du monde, et l'utiliser normalement en ayant rendu simplement sa
taille "raisonnable" pour une connexion à l'Internet.
// Charge et traîte le fichier compressé
getURL('airports.rdf.gz', drawAirportsFromFile);
Problème d'échelle des éléments graphiques lorsqu'on zoome
Souvent sur un graphique, on a besoin de pouvoir décrire textuellement une
région particulière : par exemple, écrire "Retour" quand on place le curseur
au-dessus d'une flèche... Ceci est facile pour un fichier HTML par exemple
(attribut "title").
<!-- Ceci crée un lien "Retour" avec un texte descriptif, en HTML -->
<a href="../" title="Cliquez ici pour retourner à la page principale">Retour</a>
Pour un fichier SVG, il n'existe pour l'instant rien de tel ; il faut donc
pouvoir le faire entièrement nous-mêmes. Lorsqu'on a le curseur au-dessus de
l'icône d'un aéroport, il est très intéressant de pouvoir savoir le nom de
cet aéroport.
La solution adoptée est de mettre un écouteur sur l'événement
"onzoom" : une fonction récupère alors le facteur de zoom et
redessine tous les éléments qu'on souhaite garder à la même taille (comme les
textes et les emplacements des aéroports).
ECMAScript et l'orientation objet
Au cours du codage, nous avons eu l'occasion de voir qu'ECMAScript n'est
pas véritablement orienté-objet par nature, ce qui a posé quelques gros
problèmes car il devenait parfois incapable de gérer plusieurs objets en même
temps. Il est également impossible de donner des méthodes à effectuer à la
classe Object.
// Marche
SVGElement.prototype.testMe=function(){
window.alert('Test !');
}
// Ne marche pas
Object.prototype.testMe=function(){
window.alert('Test !');
}
En l'occurence, il doit s'agir d'un dysfonctionnement, car dans la
spécification il est noté que ce doit être possible. Ceci dit, une
utilisation aussi évoluée côté-client est encore assez rare, donc on peut
supposer qu'il n'existe encore que peu d'implémentations réellement assez
puissantes.
Conclusion sur la fin du projet
Voici quelques paragraphes sur le fonctionnement du
projet, et sur les évolutions qu'on peut lui apporter.
Qu'est-ce qui fonctionne ?
L'essentiel marche, et on peut créer des données RDF concernant des
acteurs et dans une zone ciblée. Par exemple, voici une sortie RDF que peut
donner le script :
<rdf:RDF>
<!-- Situation des personnes par rapport à votre position actuelle -->
<Person>
<name>Dominique Hazel-Massieux</name>
<sameZoneType xml:lang="fr">pays</sameZoneType>
<sameZoneName xml:lang="fr">France</sameZoneName>
</Person>
<Person>
<name>Ian Davis</name>
<sameZoneType xml:lang="fr">continent</sameZoneType>
<sameZoneName xml:lang="fr">Europe</sameZoneName>
</Person>
</rdf:RDF>
Pour arriver à l'aboutissement du projet, les étapes nécessaires ont
successivement été validées :
D'abord sommairement contenues dans la page, ensuite sous forme de
fichiers externes RDF en haute définition, les informations ont été chargées
avec succès. Dans la mémoire de l'ordinateur, elles sont des tableaux de
différents objets, de façon à pouvoir les utiliser au cours du script.
Les positions des gens et des aéroports sont effectivement placées sur la
carte, en fonction des coordonnées qu'on a déterminées. Les contours des pays
n'ont pas besoin d'être dessinés pour que le script fonctionne ; on ne les
représente que pour vérification.
Quand on recherche la localisation d'un point géographique, le script
ressort la liste des zones qui contiennent ce point. Ensuite, ces zones sont
triées par précision décroissante. Exemple, pour un point (47,2), les
résultats donnent "Val-d'Oise, France, Europe" si ces trois zones existent
sur la carte. On peut ainsi chercher tous les résultats, pour chaque
personne, puis les comparer entre eux ; on trouvera ensuite des relations
telles que "vous êtes dans la même région que Bob".
Créer une page web pour décrire le projet a été rapidement une nécéssité.
Celle-ci fournit des renseignements sur l'utilité du projet, sur les
techniques qui y ont été implémentées, et est un point central pour en suivre
l'évolution tout au long de son développement.
Comment modifier le script pour soi
Définir des conditions sur les personnes
La communauté FOAF rassemblant un très grand nombre de personnes
(plusieurs milliers), il peut être utile de pouvoir les "choisir" : ne pas
prendre en compte les personnes avec qui on n'a aucune affinité, ne prendre
que les collègues de travail, etc. Pour parvenir à ce tri, il est possible
d'utiliser n'importe quel renseignement qui peut être fourni dans les
fichiers FOAF des personnes. Par exemple, on pourra ne choisir que des
personnes qui connaissent Cédric :
conditionElement="foaf:knows";
conditionValue="cédric";
Mais aussi, des personnes travaillant au W3C :
conditionElement="foaf:workHomepage";
conditionValue="w3c";
Pour ce faire, on demande dans le script, le cas échéant, une valeur
particulière dans un élément : "cédric" dans foaf:knows, ou "w3c"
dans foaf:workHomepage.
Le script "sérialise" les données et y cherche la chaîne de caractères
demandée. Ceci permet de s'y retrouver parmi les diverses formes que peut
prendre une valeur (un rdf:about, un rdfs:seeAlso, ou
un élément descendant).
Choisir un scutter
Le scutter, comme on le sait déjà, est un fichier regroupant les adresses
des fichiers FOAF des personnes qui participent. C'est un "point de départ"
pour récupérer des fichiers FOAF ; changer de point de départ peut être utile
en fonction des applications.
Suivre les pointeurs externes
RDF permet une grande décentralisation des données. On peut par exemple
donner des références à des fichiers distants avec un
rdfs:seeAlso. Mais dans ce cas, suivre toutes les références prend
un temps très conséquent (plus de 24 heures !). On jugera alors que les 3000
fichiers que nous utilisons sans cette méthode, fournissent un panel
suffisant pour vérifier le bon fonctionnement du système, et on prendra le
parti de ne pas suivre les références externes.
Comment améliorer le script
Utiliser un véritable parser
Evidemment, ce que j'ai développé n'est pas un vrai parser RDF, car (entre
autres) on ne suit pas les liens donnés par rdf:resource,
rdfs:seeAlso ou par les identifiants de type XML
(#id).
<!-- voici un rdf:resource qui appelle une ressource externe -->
<foaf:knows>
<foaf:Person>
<foaf:nick>Eric</foaf:nick>
<rdfs:seeAlso rdf:resource="http://www.perceive.net/xml/foaf.rdf" />
</foaf:Person>
</foaf:knows>
Utiliser des ontologies
On ne traite pas les ontologies — ce n'est pas le but du stage.
Ainsi, si Alice décrit sa proximité géographique à l'aéroport CDG ainsi :
<wn:nearestAirport iata="CDG"/>
On est loin de la description qu'en fait Bob :
<contact:nearestAirport>
<apt:iata>CDG</apt:iata>
</contact:nearestAirport>
Pour rendre ceci possible, il faudrait une ontologie, c'est-à-dire une
interface entre vocabulaires, qui puisse traîter des données de différentes
natures mais comprendre qu'elles ont le même sens. Ici, ceci permettrait de
comprendre que wn:nearestAirport et
contact:nearestAirport ont le même sens, mais utilisent des
syntaxes différentes pour décrire une même chose. Les travaux du W3C sur OIL
vont dans ce sens, et dépassent de loin le cadre de ce stage.
Le développement des services de proximité sur le Web
Les technologies et les vocabulaires nécéssaires à la localisation en sont
encore au tout début. De plus en plus de sociétés (publicité, centres
commerciaux, agences immobilières) s'intéressent aux services de proximité,
et projettent d'intégrer des données issues de systèmes d'informations
géographiques. On peut donc supposer que de nombreuses réponses (et autant de
nouvelles questions !) vont être données prochainement.
Avec l'avènement des GPS bon marché et l'explosion des machines portables
(téléphones, PDA), on verra certainement de plus en plus de travail effectué
dans cette discipline.
Bilan personnel de ce stage
Voici une brève conclusion sur ce que ce stage m'a
apporté.
Mon intégration dans l'entreprise
Véritable équipe internationale
C'est la première fois que je fais partie d'une équipe internationale. Ce
qui veut dire que les gens avec qui je travaille sur place ont des
nationalités et des cultures différentes ; ce qui veut aussi dire qu'en règle
générale, l'équipe n'est pas forcément sur place au complet. En effet j'ai
généralement travaillé avec des personnes basées dans d'autres pays, une
grande partie du personnel du W3C se trouvant aux États-Unis, et la majorité
de l'équipe SWAD-Europe basée au Royaume-Uni.
La communication électronique nous a permis de travailler malgré
l'éloignement géographique. Les décalages horaires doivent être pris en
compte pour pouvoir réunir en même temps les équipes d'Australie, des côtes
ouest et est des États-Unis, du Japon et de l'Europe.
Appréciation globale du travail du W3C
J'ai pu me baigner à loisir dans la culture d'entreprise du W3C, et en
apprécier de nombreux aspects, grâce notamment à la confiance et la
bienveillance dont m'ont honoré les membres de l'équipe. Être au W3C, c'est
travailler dans une équipe jeune et compétente, sur des sujets passionnants.
C'est aussi travailler très dur, ne pas compter ses heures et ramener de la
besogne à la maison.
L'activité du W3C résulte d'un compromis constant entre la puissance et la
simplicité, entre la concision et la clarté, et est guidée par l'idée que
tout le monde doit pouvoir participer à l'Internet, sans aucune distinction.
Par exemple, ce travail doit permettre de réduire les écarts entre les
langues les plus utilisées sur l'Internet, et les autres (contrairement à ce
qu'on s'imaginerait, nous ne seront finalement peut-être pas forcés
d'apprendre tous l'anglais...). C'est en tous cas, un travail essentiel pour
l'informatique du proche avenir.
Ma participation dans l'équipe
J'ai essayé de participer le plus ouvertement possible aux activités de
l'équipe, en utilisant les moyens dont je disposais : en général, cela
consistait à suivre les conversations techniques sur IRC, ce qui a permis
d'une part de profiter des nouvelles idées, d'autre part de pouvoir démontrer
mon implication active dans le groupe, gage d'intégration important pour un
stagiaire. Les e-mails ont également été un moyen privilégié pour partager
commentaires, recherche de dysfonctionnements et avis divers.
Hors communication électronique, la réunion du Team SWAD-Europe (en
juillet) a été une excellente occasion de faire connaissance avec les autres
membres, et de faire une brève présentation des progrès sur mon projet.
Le contrôle de mon projet
Le codage : une épreuve chronométrée
Le codage du script a été un véritable parcours minuté. En voici la
chronologie des épreuves !
- apprendre le RDF : il était nécéssaire de saisir les concepts et les
outils avant de commencer quoi que ce soit ;
- codage : se dépécher de coder pour pouvoir écrire quelque chose
d'intéressant sur la page web ;
- maintenance : à chaque point de codage important réalisé, mettre à jour
de la page web pour exposer les nouvelles possibilités ;
- réussir à coder quelque chose d'utile pour pouvoir le présenter à
l'équipe lors du meeting ;
- clore le projet suffisamment rapidement pour pouvoir envoyer un e-mail
aux listes de diffusion qui pourraient être intéressées par un tel
travail.
Maîtrise de nouveaux outils
Le travail au sein du W3C m'a amené à utiliser de nouveaux outils, et à
réfléchir autrement au cours de l'élaboration d'un projet (d'ordinaire je
travaillais souvent soit seul, soit sous couvert de confidentialité). Quand
les bases de ce projet furent jetées, et que le script eut un peu avancé,
j'ai pris l'initiative de créer une page web pour expliquer les objectifs,
les points traités, et les points problématiques de ce travail — ainsi
qu'une capture d'écran montrant le script en action. Ces informations, mises
à jour régulièrement, ont été proposées à des moteurs de recherche, pour
optimiser l'utilité de ce projet ouvert.
J'ai appris à me servir d'un CVS (un outil de travail collaboratif), et de
programmes d'envoi (upload) de fichiers sur le Web utilisant la
méthode HTTP "put". Mes pages web ont été également affichées avec une
feuille de style CSS "maison". Ces outils, communément utilisés par le
personnel du W3C, participent à sa couleur d'entreprise.
Une vision exhaustive du projet
Lors de ce travail, j'ai pu apprécier plusieurs aspects différents :
- le codage (une partie connue puisque j'ai codé depuis 5 ans) ;
- la présentation du travail, une partie assez exceptionnelle puisque
rarement formelle, sinon par exemple au cours d'une soutenance de stage.
Elle permet de remettre en question les objectifs importants, et de
clarifier son travail vis-à-vis des membres de l'équipe ;
- la publicité et le maintien d'une "présence", quelque chose que
j'ignorais tout à fait, et que je supposais séparée du projet lui-même.
Cette discipline, qui a ses propres impératifs de forme, de contenu et
d'emploi du temps autour du projet lui-même, est pourtant impérative
(ici, pour que le travail effectué ne soit pas vain).
Les risques liés à la privacité
Ces nouvelles technologies peuvent une fois de plus, malheureusement, être
utilisées à mauvais escient. Ce n'est pas un problème nouveau, mais ici c'est
la puissance et l'étendue du réseau de métadonnées qui pourrait inquiéter, en
regard du respect de la vie privée des individus qui les mettent à
disposition.
On connaît par exemple les méthodes des pirates informatiques pour
récupérer des adresses e-mail sur des pages Web. Ils revendent ces listes
d'adresses à des sociétés qui les "arrosent" ensuite de messages
publicitaires non sollicités. Imaginez qu'une telle personne utilise le Web
Sémantique pour le même dessein : elle y trouverait un véritable "filon" de
milliers d'adresses clairement exposées.
Pour contourner ces utilisations malveillantes, il est possible de crypter
ces adresses.
// Les deux assertions ci-dessous sont équivalentes
<foaf:mbox>mailto:cedric2003@ckiss.net</foaf:mbox>
<foaf:mbox_sha1sum>fc2b6e5e9b9b429fa3c45ba7ac9e8e91c4297ff5</foaf:mbox_sha1sum>
Mais le problème ne s'arrête pas là. Par exemple, dans le vocabulaire de
FOAF, existe un élément foaf:myersBriggs, qui comme son nom
l'indique, contient le résultat du test de personnalité de Myers-Briggs.
Imaginons qu'une société ait besoin de choisir entre deux candidats pour un
même poste : elle pourrait utiliser un moteur de recherche pour trouver les
métadonnées sur les deux personnes, et voir que l'un est un "INTJ" et l'autre
un "ENPJ", et y introduire un critère de préférence.
Voici un test d'embauche réduit à sa plus simple expression. On peut
espérer que la simplicité que créera le Web Sémantique, n'aboutira pas au
simplisme dans les relations humaines.

Sur le port d'Antibes.
Petit lexique des abréviations
- CSS
- CSS (Cascading StyleSheets) est un langage de mise en page.
- CVS
- Un CVS (Concurrent Versioning System) est un outil collaboratif de
gestion de différents révisions de fichiers.
- DOM
- Le DOM (Document Object Model) est une interface neutre par rapport
au langage et à la plateforme, qui permet à des programmes et à des
scripts d'accéder et de modifier dynamiquement le contenu, la structure
ou l'apparence (style) des documents.
- GIS
- Geographic Information System : intègre des données dans un espace
géogrpahique.
- HTML
- Le HTML (HyperText Markup Language) est le langage de création de
pages Web, qui permet la mise en forme de données, l'intégration de
données multimédia, et l'établissement d'hyperliens entre les
pages.
- HTTP
- HyperText Transfer Protocol est le protocole incontournable qui
permet le transfert des pages sur le Web.
- IRC
- Internet Relay Chat : dialogue (textuel) en direct sur le réseau
Internet.
- MathML
- MathML (Mathematics Markup Language) est un langage à balises pour
écrire des formules mathématiques complexes. Il peut être intégré dans
une page web.
- OIL
- Ontology Interchange Language : langage en cours de conception, utilisé pour
décrire des interconnexions entre vocabulaires.
- RDF
- Resource Description Framework : langage de description de
ressources, à la base du Web Sémantique.
- SWAD
- Semantic Web Advanced Development
- Web
- Le W3C définit le Web comme l'univers des informations accessibles
par réseau.
- XML
- XML (Extensible Markup Language) est un format de données simple et
flexible, dérivé de SGML (avec des balises qui délimitent les champs
d'informations).
- XSL
- XSL (Extensible Stylesheet Language) est un standard du W3C qui
permet de transformer un document XML pour y ajouter un style, en
changer la structure, etc.
Bibliographie
- Spécification
SVG
La définition langage SVG (site en anglais).
- Spécification RDF
La définition du langage RDF (site en anglais).
- Spécification DOM
La définition du Document Object Model (site en anglais).
- FOAF Project:
Friend-of-a-Friend (Jim Ley)
Une implémentation réussie de RDF, déclinée entre autres en graphiques
SVG (site en anglais).
- FOAF Project: Friend-of-a-Friend
developer
De nombreux textes et ressources traitant de FOAF (en anglais).
- When
is a Point Inside a Polygon?
Méthode pour calculer si un point est à l'intérieur d'un polygone (site
en anglais)
- RDF Interest Group
Le groupe des personnes et des équipes intéressées par le développement
de RDF et du Web Sémantique (site en anglais).
- Geowanking
La liste des personnes et des équipes intéressées par l'utilisation de
données géographiques informatisées (liste en anglais).
- The Virtual Terrain Project
Outils et ressources libres pour les enthousiastes de GIS (site en
anglais).
- DevGuru,
section Javascript
Une bonne référence des fonctions, méthodes et objets
Javascript/ECMAScript (site en anglais).
- Digital Chart of the
World
Contours des pays (formes politiques), en format propriétaire (site en
anglais).
- UTF-8
Konvertierung mittels Javascript
Outil de conversion en ligne utilisé pour convertir les noms des pays en
français ISO Latin vers l'encodage international UTF-8 (site en
allemand).
- Pattern
Matching and Regular Expressions
Commandes puissantes et rapides pour formater des chaines de caractères
— comme une liste de coordonnées géographiques (site en
anglais).
- SWAD-Europe Wiki
Travail collaboratif sur le projet SWAD-Europe (site en anglais).
À propos de ce fichier XHTML
Si vous lisez ce fichier sur un ordinateur, c'est
certainement au format XHTML.
Qu'est-ce que XHTML ?
XHTML est une reformulation du HTML en XML. C'est donc un format utilisé
pour créer des pages web. Utilisé avec les feuilles de style CSS, XHTML
permet de séparer le contenu de la page de la mise en page, ce qui lui permet
d'avoir plusieurs applications avec les mêmes données.
Cette page a été écrite de deux manières : avec un éditeur de texte, et
avec le navigateur/éditeur du W3C, Amaya.
Bénéfices de XHTML
XHTML est un format tout à fait recommandé pour écrire un tel rapport : il
peut intégrer des images, des textes mis en forme, et d'autres types
d'applications multimedia, avec en plus toutes les fonctionnalités des pages
web HTML.
Utiliser XHTML pour écrire ce fichier donne l'assurance qu'il est lisible
par tous, et qu'il ne sera pas inutilisable dans plusieurs années, parce que
tel ou tel éditeur de texte aura entre-temps changé de format...
Applications de XHTML
Avec les CSS Media (feuilles de style différentes en fonction du
medium d'affichage), on peut demander à la page d'afficher des informations
différentes à l'écran, sur l'imprimante, etc. mais depuis la même page.
Le format XML peut aussi s'exploiter : on peut grâce à XSLT créer la table
des matières, ou encore les transparents correspondant à la présentation.
Il peut de plus, évidemment, être publié directement sur l'Internet.